State Table (状态表)
结合使用依赖图和状态表 阅读代码时,程序员可以利用前文讨论的依赖图和状态表厘清程序脉络,以减轻工作记忆的认知负荷。 两种方法的侧重点有所不同:依赖图主要用于判断代码的组织方式,状态表则主要用于判断代码执行的计 算。
状态表 for WM: 加工运算
有时候,困惑的根源不在于代码结构,而在于代码执行的运算。这是大脑缺乏信息加工能力的标志。
使用状态表的目的不是判断代码结构,而是判断变量值。代码中的每个变量在表中占据一列,每个步骤 在表中占据一行。

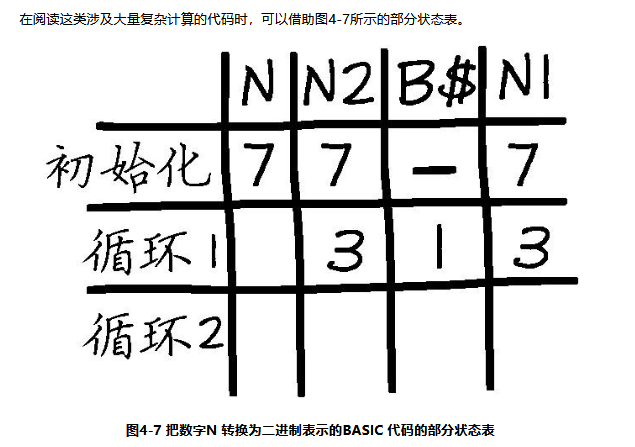
第1步:列出所有变量。 如果已经为这段代码绘制出4.3.1节讨论的依赖图,则很容易列出变量,因为依赖图中已经用同一种颜色 圈出了所有变量。 第2步:创建状态表并在每列填入一个变量。 如图4-7所示,每列填入一个变量并记录变量的中间值。 第3步:在每行填入一个不同的代码执行过程。 涉及复杂计算的代码往往也包含一些复杂的依赖关系,例如与计算有关的循环或复杂的if语句。状态表 的每一行代表不同的依赖关系。以图4-7所示的状态表为例,第1行代表初始化操作的值,第2行和第3行分 别代表两次循环的迭代值。又如,状态表的一行既可以代表复杂的if语句中的某个分支,也可以代表一段连 续的代码。而对于极其复杂或极其简短的代码,状态表的一行甚至可能代表一行代码。 第4步:阅读各部分代码,然后把每个变量的值填入表中合适的行和列。 从头到尾阅读代码,计算出更新后的各个变量值并填入表中每一行。大脑分析程序执行的过程称为跟踪 或认知编译。利用状态表跟踪代码时,程序员很容易略过某些变量,只把部分值填入状态表,但是最好不要 这样做。认真填写状态表有助于程序员更好地理解代码,一张完整的状态表能够减轻工作记忆的负荷。再次 阅读程序时,程序员可以借助状态表专心研究程序的连贯性,而不必纠结于具体的计算过程。